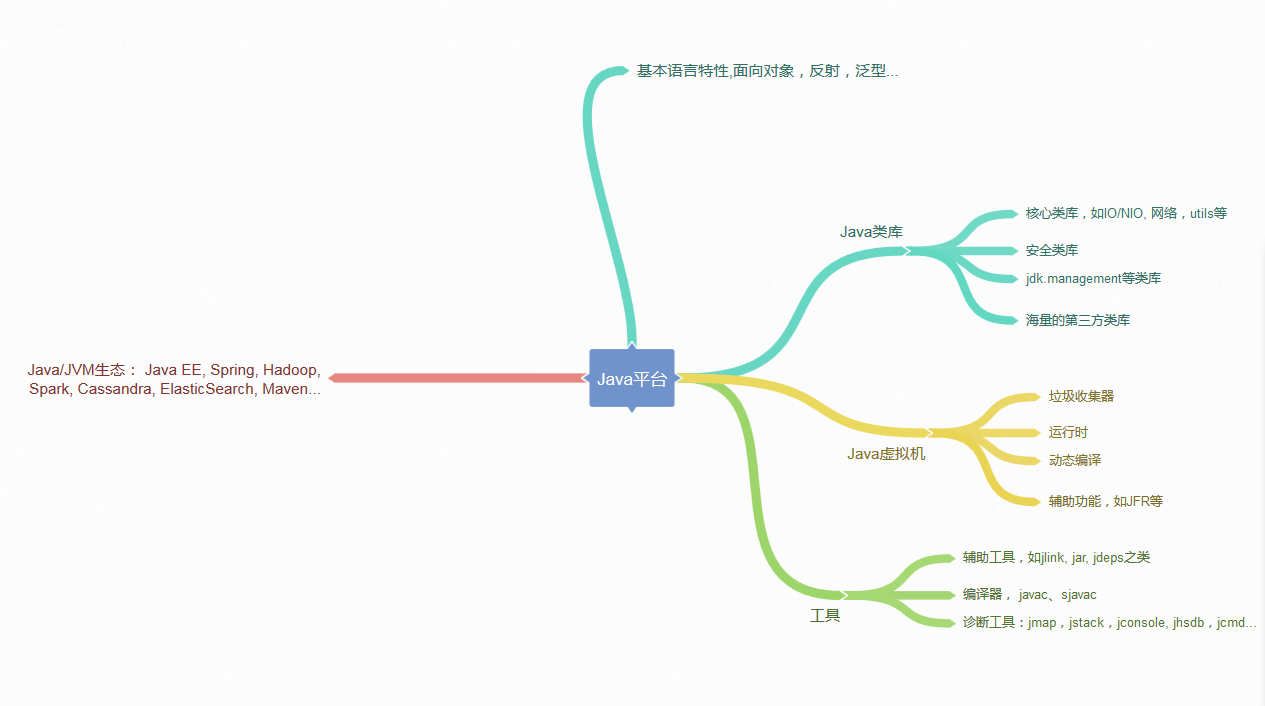
V8的内存模型
要搞清楚V8的垃圾回收,先要搞清楚V8的内存模型是什么样的。
V8的内存限制
一般开发语言中,基本内存使用上没有什么限制,然而在Node中却只能使用部分内存(64位系统下约为1.4G,32位0.7G),所以一般情况Node不能操作大内存。这其实是V8的限制,这个限制在浏览器中绰绰有余,但是Node作为后端开发使用,就显得有点不够了。
V8做这个限制的根本原因在于V8的垃圾回收机制限制。按官方说法,以1.5G的垃圾回收堆内存为例,V8做一次增量垃圾回收需要50毫秒以上,做一次全量垃圾回收甚至需要1秒以上。这些垃圾回收会引起JavaScript线程暂停执行,应用的性能和响应能力都会直线下降,所以直接限制堆内存在浏览器使用是一个好的选择。不过这个限制也不是不能打开,V8依然提供了选项让我们使用更多的内存,可以通过Node启动时传递参数来修改最大内存空间。
V8的对象分配
当我们在代码中声名变量并赋值的时候,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,知道堆的大小超过V8的限制为止。
V8的内存分代
在V8中,主要将内存分为新生代(64位64MB,32位32MB)和老生代(64位1400MB,32位700MB)两代。新生代中的对象生命周期比较短,老生代的生命周期比较长或者是全部对象常驻内存中。V8堆的大小就是就是新生代内存加老生代内存之和。
V8的垃圾回收机制
实际情况中没有一种算法能够胜任所有场景,所以有了V8的内存分代。不同生命周期的对象采用不同算法来来进行垃圾回收才能得到最好的效果。
V8主要垃圾回收算法
Scavenge算法
新生代内存中的对象主要通过Scavenge算法进行垃圾回收。
新生代使用Scavenge算法进行回收。在Scavenge算法的实现中,主要采用了Cheney算法。
Cheney算法算法是一种采用复制的方式实现的垃圾回收算法。它将新生代内存一分为二,每一部分空间称为semispace。在这两个semispace中,一个处于使用状态,另一个处于闲置状态。处于使用状态的semispace空间称为From空间,处于闲置状态的空间称为To空间,当我们分配对象时,先是分配在From空间中。当开始进行垃圾回收算法时,会检查From空间中的存活对象,这些存活对象将会被复制到To空间中,而非活跃对象占用的空间将会被释放,完成复制后,From空间和To空间的角色发生对换。使用Cheney算法时,总有一半的内存是空的。但是由于新生代很小,所以浪费的内存空间并不大。由于新生代中的对象绝大部分生命周期很短,是非活跃对象,需要复制的活跃对象比例很小,所以其时间效率十分理想。复制的过程采用的是BFS(广度优先遍历)的思想,从根对象出发,广度优先遍历所有能到达的对象。
但是在每一次复制之前,将会先做以下检查:
25%是因为复制完成后,To空间将会变成From空间,所以需要给From空间预留足够的内存在分配新对象。
Mark-Sweep & Mark-Compact
Mark-Sweep是标记清除的意思,分为标记和清除两个阶段。在标记阶段遍历所有对象,并标记活着的对象。清除阶段只清除没有被标记的对象。
Mark-Compact是标记整理的意思,Mark-Sweep清除对象后会存在一个问题,内存空间出现不连续的情况。所以Mark-Compact的作用就是在标记阶段完了之后将被标记的对象全部移动到内存空间的一侧,清除阶段只需清理另一侧没有标记的对象。Mark-Compact由于移动对象效率不够高的原因,导致只有在空间不足以对从新生代晋级过来的对象进行分配时才使用Mark-Compact。