Overview
Todays topic is about index improvment, so first we need to know some backgrounds.
Background
Index
We have more than 100,000 products in production, before the full index will take almost 2 hours, so client only build index once in each day. The issue is if business change some data before do a idnex, it will cause PLP data is not match with PDP.
So business want to reduce the index time, and they want to build index for each 2 hours.
Request
At the same time, some of categories products have many child SKUs, like clothes, shoes categories. We only have 3 kind of properties need to display on PLP:
- Some product properties, like display name, brand.
- Some of properties on the product’s default SKU, like: default image.
- Other properties: al of the SKU colors on product, and all of the SKU price range.
Means if a customer visit above categories, it will return so many useless SKUs with useless properties.
See a example: jsp_ref.
So business want to reduce response for those category request to improve performance.
There is one thing you guys need to know:
You guys should know our site only return results as product level, means each item is a product. But in our index, the each record is SKU level.
See a example: jsp_ref.
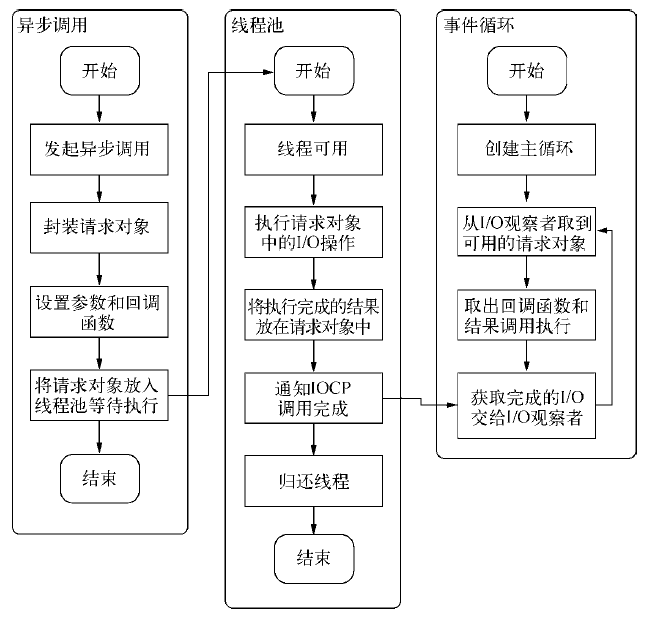
So how to implement this by Endeca:
Endeca OOTB need define a aggregate property, in Falabella, we are using product.repositoryId as aggregate property,
each record has a product.repositoryId property, Endeca will use this property to merge SKU as product group by this property.
See a example: jsp_ref.
Process
Next we need to know the process about index and request before do index improvement and after index improvement.
Full index
Before
- Get all products by a RQL, see Component.
- Filter invalid products, see Component.
- Build each record and each property base on the XML file, and write record to CAS(CAS is a mid-database for index input). see XML file, accessor and CAS.
- Get data from CAS to build index.
After
- Execute a procedure to calculate all valid product in a table, see Procedure.
- Get all valid products form the table, see Component.
- Build each record and each property base on the XML file, and write record to CAS(CAS is a mid-database for index input). see XML file, accessor and CAS.
- Get data from CAS to build index.
Advantage
Most of time spent in step 2 and 3. in step 2, the Procedure time must less than Java code. In step 3, we removed some many useless properties to reduce inde time.
Disadvantage
Procedure is mote difficute than Java code, so the maintenance costs will increase.
Partial index
Before
- Change a property by business.
- Descriptor listener will write a data to a OOTB table at SKU level, see Descriptor and listener.
- Get all SKUs from above table.
- Build each record andeach property base on the MXL file and write record to CAS.
- Get changed data from CAS to do partial index.
After
- Change a property by business.
- Descriptor listener will write a data to a new table at product level, see Descriptor and listener.
- Do a partial procedure to get data from above table and get all SKUs of the product to write the OOTB table.
- Build each record andeach property base on the MXL file and write record to CAS.
- Get changed data from CAS to do partial index.
We can find that there is no performance improvement here, the only change is we add a new table and use it as a mid-table to write data to OOTB table, the reason I will explain after.
Request
Before
- Send a Endeca request with a parameter as “ALL”, see the parameter.
- Aggregate record by product.repositoryId, and return all SKUs under the product.
- We can get all product properties and all of the SKUs properties, see Record Object.
- Display on site.
After
- Add a aggregate property when build index on product, see structure and code.
- Send a Endeca request with a parameter as “ONE”, see the parameter.
- Aggregate record by product.repositoryId, and return all SKUs under the product.
- We can get all properties what we need, see Record Object.
- Display on site.
Advantage
Reduce response, because we need return properties what we need.
Disadvantage
We need to change partial index logic, because each record is SKU level has a property product.aggregateData, the aggregateData property has all of the SKUs prices and colors.
Like if business change a SKU A price under product A, we need do partial index for all of the SKUs under product A, this is the reason why we do partial index change in above.
Design
Full index
Table
fbl_srch_sku_published
Repository
Add a new descriptor searchSKUPublished in FalabellaRepository.
Add a new property “publishedChildSkus” on product, no need use this property, use “filteredChildSkus” to get all valid SKUs.
Procedure
PROC_CALC_PUBLISHED_SKU
Component
CalculatePublishedSku
IndexedItemsGroup
SkuPublishManager
ProductCatalogSimpleIndexingAdmin
Partial index
Table
fbl_srch_update_queue
Repository
Add a new descriptor searchSKUQueue in IncrementalItemQueueRepository.
Procedure
PROC_CALC_PARTIAL_SKU
Component
CalculateParitalSku
ProductCatalogSimpleIndexingAdmin
Request
Component
SkuAggregatedDataAccessor
FBLPriceListMapPropertyAccessor
ProductColorSKUsAccessor