

之前在微信上看到一篇叫批处理已死,Kafka 当道的文章,刚好我们的项目马上要到cyber了,增量索引在每五分钟之内会有10w的数据量,导致每编一次增量索引的时间都要1个小时以上。所以想到是不是可以参考kafka来优化我们的增量索引。
什么是kafka
什么是 Kafka?Apache Kafka 是 LinkedIn 开源的分布式消息系统,在 LinkedIn 目前每天处理几十万亿条的消息,并且已经部署到了世界范围内成千上万的组织之中,包括财富 500 强的公司。基本上成了一种工业标准。
Kafka 的基础是 log 的理念,log 是只能往上追加(append),完全有序的数据结构。log 本身采用了发布 - 订阅(pubsub)的模式,发布者能够非常容易地把不可变的数据往 log 上追加,订阅者可以维护自己的指针,以便处理当前的信息。
增量索引模型
优化前
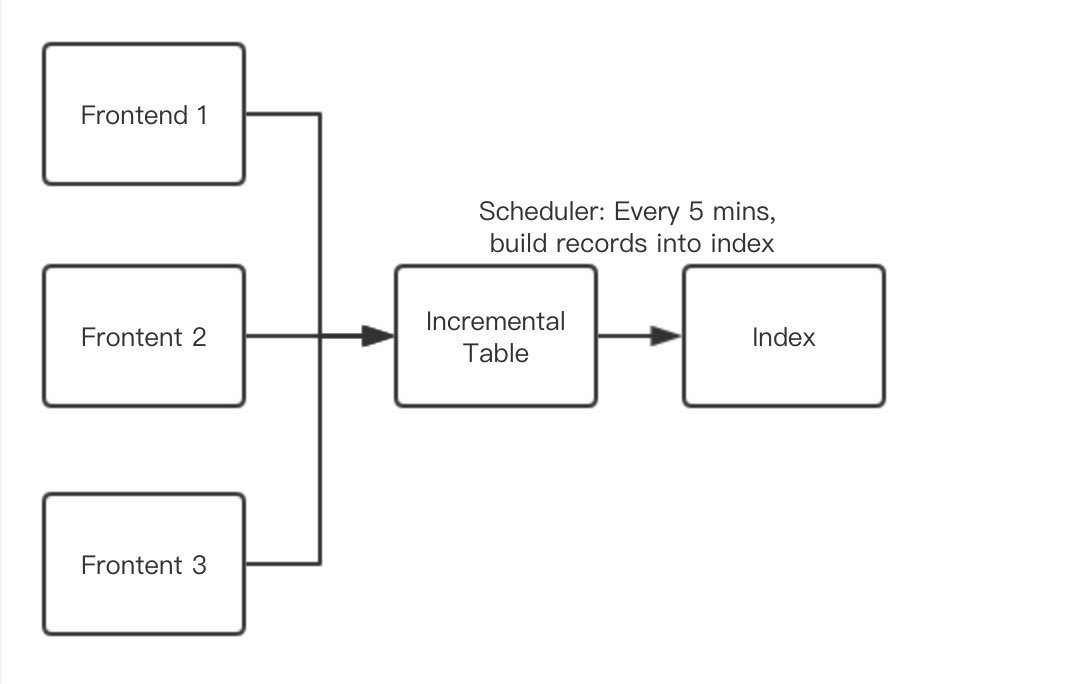
优化前其实思路很简单,前端或者任何地方触发了一个产品需要增量索引,就将该产品的ID添加到Incremental Table中,然后在系统后台有一个Scheduler在每五分钟执行一次将表中的数据编入索引。这个方案在平时没什么问题,但是到了cyber的时候,会有大量产品没有库存和价格的变动,导致每五分钟内的需要进行增量索引的产品过多,每次大概在需要一个小时以上的时间。
优化后
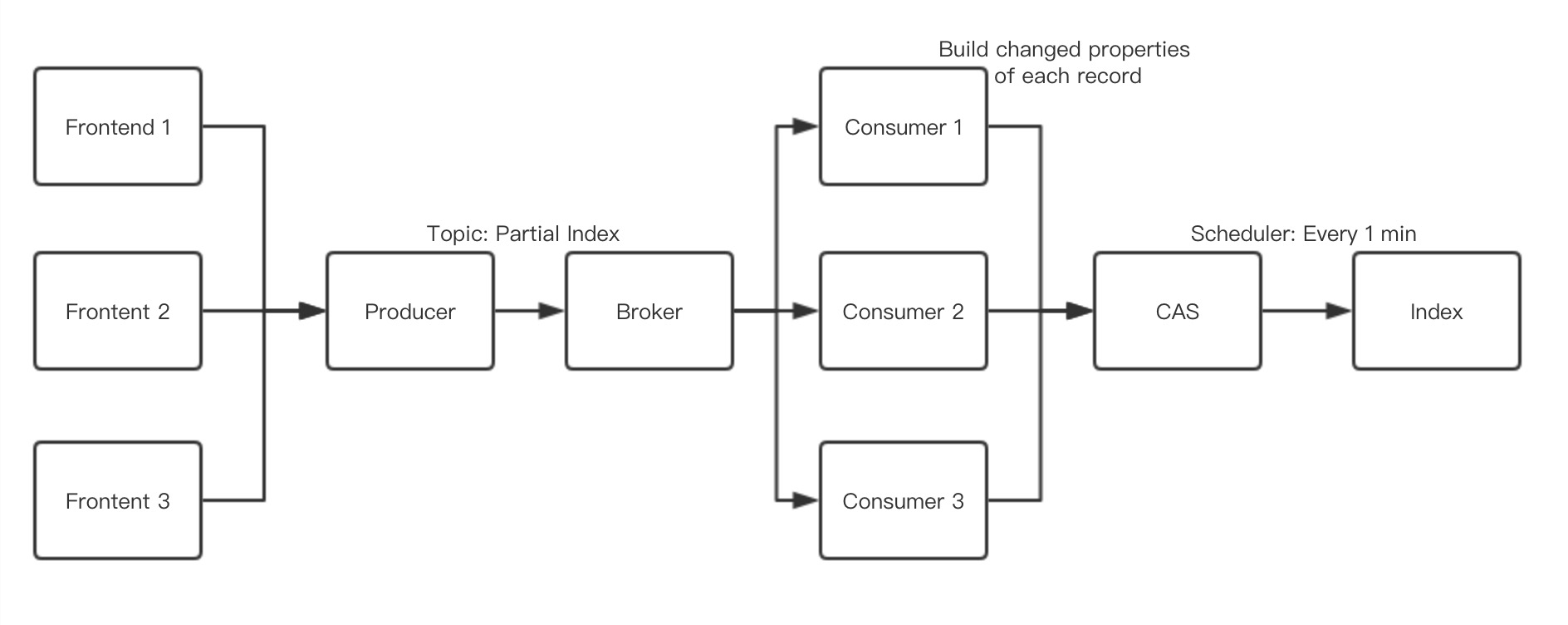
优化后就是将整个原本写入table的产品写入kafka之中,然后用kafka的消费者Group来消化这些产品并build产品的属性到我们的CAS之中(一个nosql数据库),最后再由Scheduler将CAS数据读取出来编入索引。因为时间消耗最大的地方就是在对产品属性重新计算的时候,而我们把这部分横向扩展成了kafka的消费来来消费这部分,极大提升了增量索引的时间,优化后时间,基本能做到实时处理所有数据。(Scheduler设置每分钟的原因是因为磁盘读写,因为增量索引是直接往索引文件追加,并复制到多个索引备份中,时间大概为1分钟。)